
自然言語処理の分野では,人間があらかじめ解析を行ったデータを訓練例として,機械学習によって,人間の解析を模倣するプログラムを自動学習する試みが盛んに研究されています.
決定木学習は,そのような機械学習の手法の中でも,最も基本的なもののひとつです.
このページでは,決定木学習を用いて,言語解析の優先付けを行う手法を説明します.
まずは,準備として,確率モデルによって,言語解析の優先付けを行う方法について考えていきましょう.
[1] 形態素解析,句構造解析,係り受け構造の解析,いずれの場合にも共通することは,文全体の解析結果に確率値を与えるということです.
この文全体の確率は,例えば,係り受け構造の解析なら,「ある文節がある文節に係る確率」のような,より小さい単位に対する確率値の積で計算されます.
そして,解析結果に複数の可能性がある場合は,確率値最大の解析結果を優先します.

[2] では,係り受け構造の確率モデルを見ていきましょう.
この場合,文全体の係り受け構造の確率は,上に示したような3つの係り受けの確率の積で計算されます.
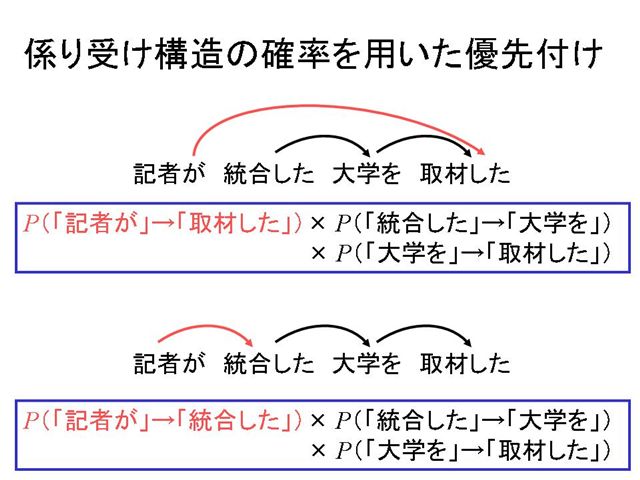
[3] 先ほどの例で,係り受け解析の結果に複数の可能性が考えられる場合を見てみます.
上のスライドの2つの解析結果を比較すると,文全体の係り受け構造の確率は,「記者が」の係り受けの確率の部分が異なります.

[4] 実際に確率モデルを用いて,人間の言語解析を模倣するプログラムを学習する方法について,その全体像が上の図になります.
では,この内容について,次に,具体例を使って,順にみていきましょう.


[6] P(「記者が」→「取材した」)の具体的な値を求める(パラメータ推定)方法を説明しましょう.
一つ目のイコールの後のPは,Xという条件が満たされているときに,係り受け関係が存在する確率を表しています.
このXは,[5]の図の例文で,「記者が」と「取材した」が例文中にどのように現れているのかを
「左文節」「右文節」「文節間距離」
の観点で書き下したものです.
そして,正しい係り受けを付与した大量の文を用いて,それぞれの頻度を調べて,二つ目のイコールの後の値を計算します.
[7] では,上記の2つの解析結果のどちらがもっともらしいのか判断する,という状況について考えましょう.
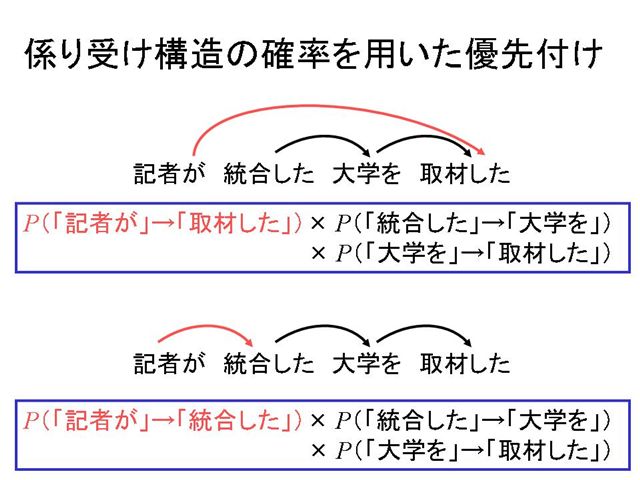
[8] 具体的には,二つの解析結果の間で,文全体の係り受け構造の確率を比較する,ということをします.
P(「記者が」→「取材した」)
のパラメータ推定の方法は,[6]で説明しましたので,次は,同じように
P(「記者が」→「統合した」)
のパラメータ推定を考えましょう.

[9] 「記者が」と「統合した」が例文中にどのように現れているのかを
「左文節」「右文節」「文節間距離」
の観点で書き下すと上の図のようになります.
[6]の
P(「記者が」→「取材した」)
のパラメータ推定のときと同じように,確率値を計算します.

[10] 今まで説明した方法で,係り受けの確率が求まるから,これで係り受け解析ができる.よかったよかった.・・・.でも,ちょっと待ってください.この調子でパラメータ推定すると困ったことが起こります.
例えば,具体的な語彙として,名詞が10万個,サ変名詞が1,000個あったとしましょう.そうすると,組み合わせの数は1億個にもなってしまいます.
正しい係り受けを付与した文を,
ものすごくたくさん用意することができれば,すべての組み合わせがデータ中に現れるかもしれませんが,そうでなければ,データ中に現れない組み合わせが数多く発生し,これらのパラメータを推定できません.
したがって,モデルの複雑さをできるだけ緩和しておく必要がどうしても生じます.
では,「主辞」のところに具体的な言葉を用いずに,品詞だけにしてみると,上の図にあるように,モデルの複雑さがだいぶ緩和されます.

[11] 一方,こちらの図が,「主辞」のところに具体的な言葉を用いるモデルです.
一般に,確率モデルを使って,人間の言語解析を模倣するプログラムを自動学習するためには,モデルをどれくらい複雑にしておくか,という,モデルの設計の作業がとても重要です.
モデルの設計のよしあしによって
,学習結果のプログラムの性能が大きく左右されることになります.
そこで,決定木学習のような,機械学習の技術の出番になります.
機械学習の技術により,モデルをどれだけ複雑にする必要があるかを,自動的に決めることができるようになります.
つまり,「主辞」のところに具体的な言葉を用いるべきか,品詞だけにすべきか自動的に決めてくれるのです.
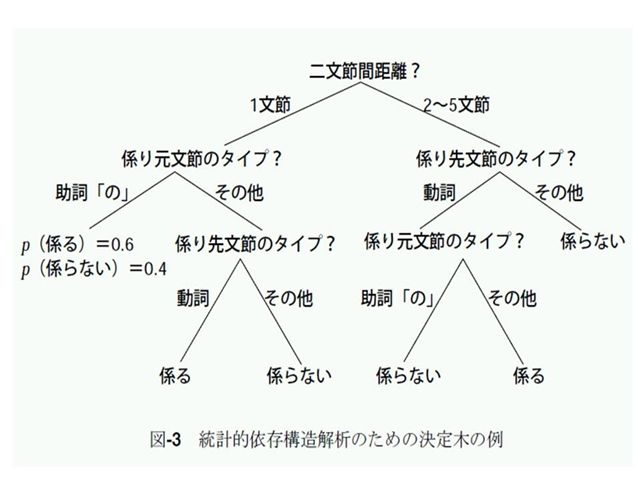
[12] ここで,決定木学習の話を思い出してください.決定木学習は,調べる必要のある属性をなるべく少なくし,しかもなるべく決定的に目的となるクラス(この場合,係るか係らないか)を決めてくれる規則もしくは確率分布を学習してくれます.
実際に,決定木学習によって,人間の係り受け解析を模倣するプログラムを学習した結果が上の図です.
[8]の例で,「記者が」が「取材した」に係るのかどうかを,この決定木で判定しましょう.そうすると,
そうすると,「係る」と判定されることになります.うまくいっていますね.
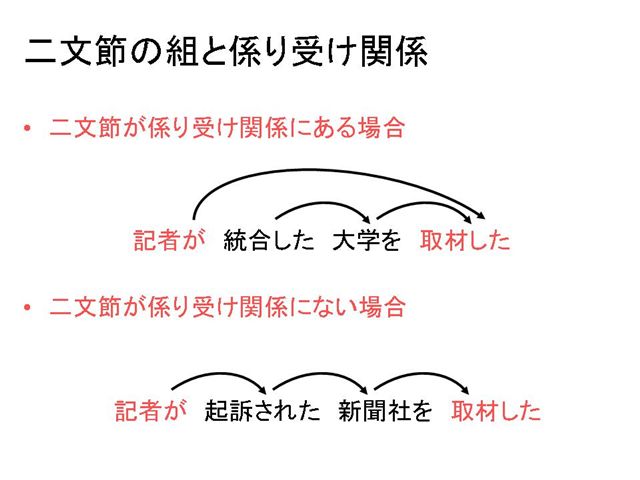
[5] ここで,