
一般的な分類問題に対して,機械学習を適用する例を見ていきましょう.

では,職業からその人が解約するかどうかを判定できるでしょうか?
残念ながら,YES・NOとも,解約・非解約が混ざっていて,職業からその人が解約するかを予想することはできません.

ところが,年齢に注目すると,40歳を境にして,解約する人と解約しない人がきれいに分かれます.
つまり,年齢が40歳未満の人は解約の恐れがあると判断できるので,解約されないように対策を打つことができます.
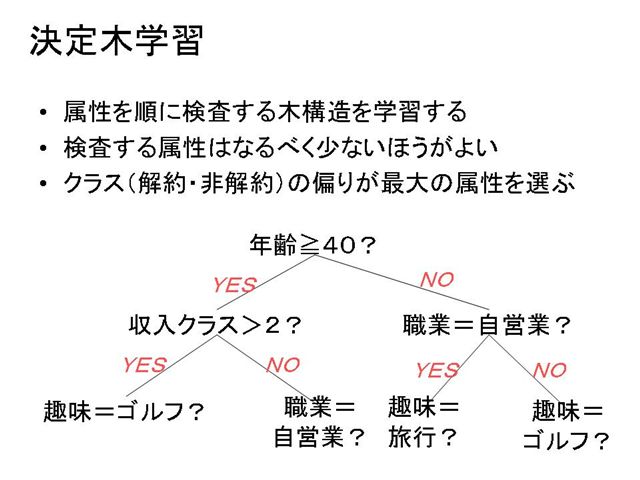
ここでは,属性を順に検査する木構造を「学習」によって自動的に作り出すことを考えます.これを決定木学習といいます.
コンセプトは,検査する属性はなるべく少ないほうがいいということと,クラス(解約・非解約)の偏りが最大の属性を選ぶということです.
先ほどの例ですと,「年齢≧40」という属性を調べると,YESの方は非解約ばかり,NOの方は解約ばかりと偏りが最大ですので,まず,年齢の属性を調べるのがよいということになります.

ここで節点のエントロピー(複雑さ)を考えます.
ある節点Tで,解約と非解約のデータが半々ぐらいだと,エントロピーは大きくなり,逆に,例えば解約のデータばかりだと,エントロピーは小さくなります.
実際には,節点ごとにエントロピーの減少が最も大きくなる属性を選んでいくことで決定木を作成します.
節点のエントロピーはスライドの上の式で計算します.
自然言語処理の分野では,人間があらかじめ解析を行ったデータを訓練例として,機械学習によって,人間の解析を模倣するプログラムを自動学習する試みが盛んに研究されています.次のページででは,そのごく一例を紹介します.
これは,プロバイダの解約データです.それぞれの人物に対して,属性(性別,年代,職業,住所,趣味,収入)とその人がプロバイダを解約したかをまとめたデータです.例えば,上から2つめのデータは,ある30代の男性(自営業,趣味は旅行,収入のクラスは3)の人はプロバイダを解約したということを示しています.
このデータをもとに,ある別の人がプロバイダを解約するかどうか,推定することができるでしょうか?解約しそうな人を推定できれば,プレゼントやキャンペーンをして,解約を防止することができるかもしれません.
このように,与えらた属性データから対象がどのクラスに属するのかを判定する問題を,分類問題といいます.